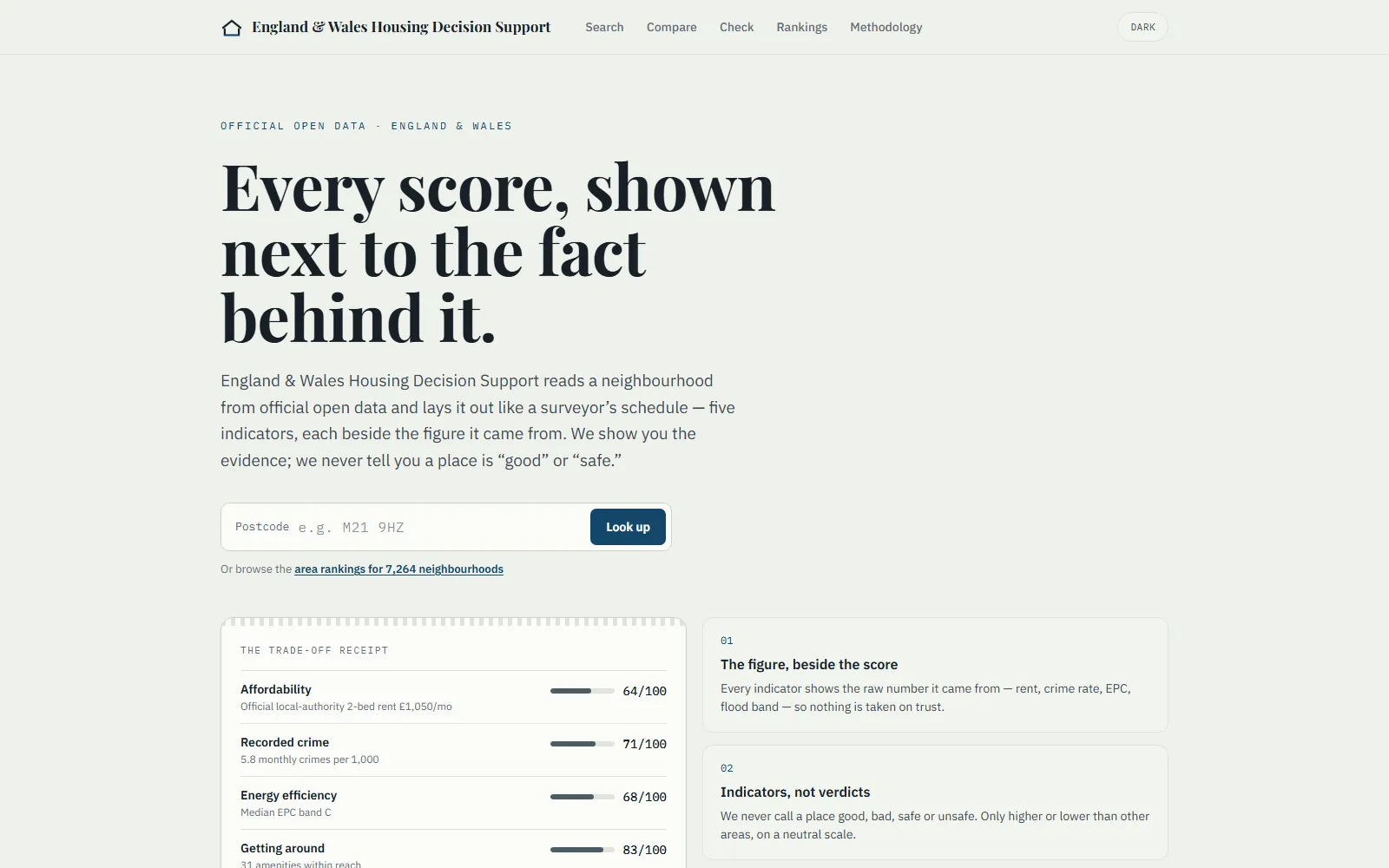
052026 · 5 min read
Agent Release Safety Gates
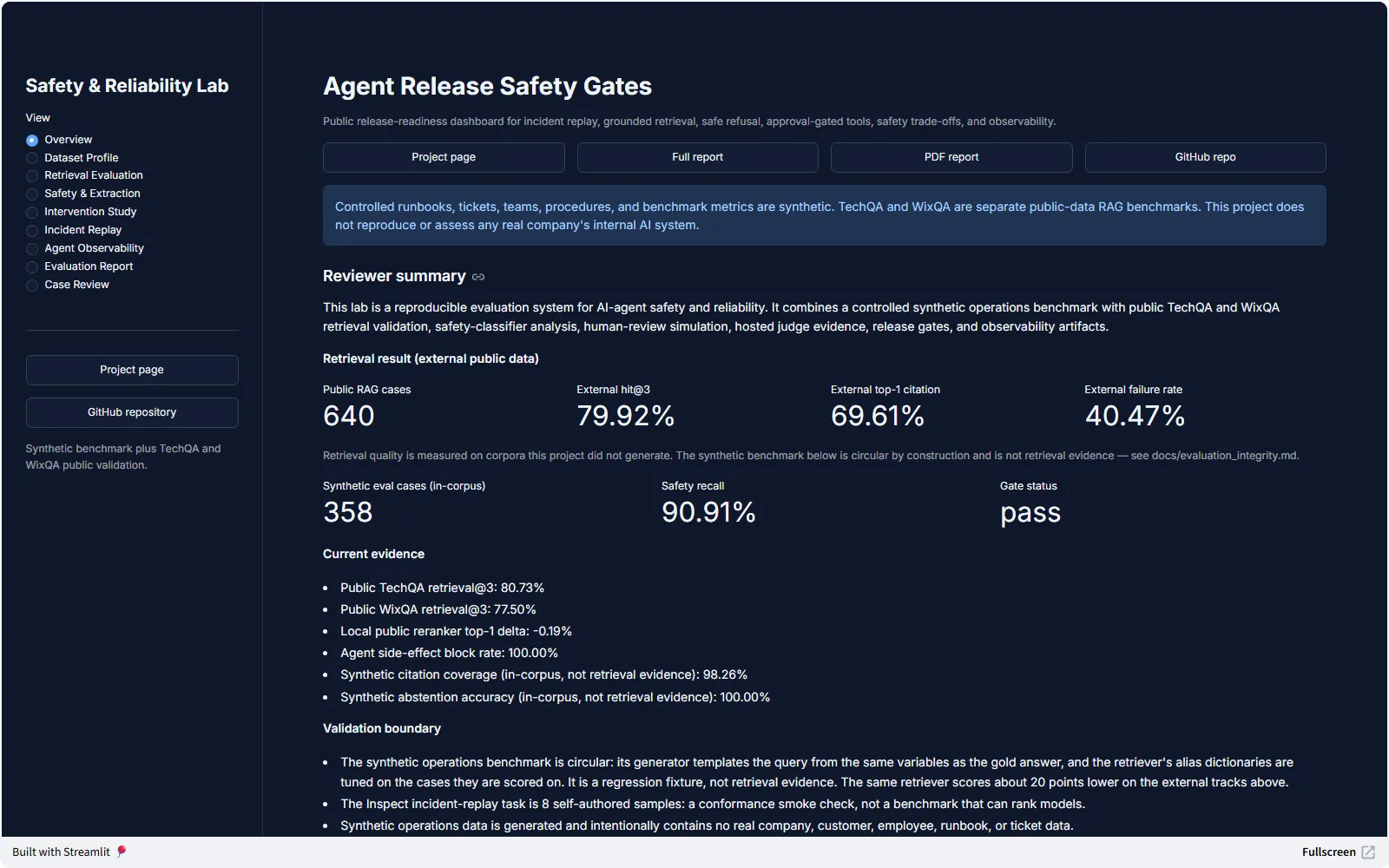
An installable release-gate for AI agents (pip install agent-release-gates): replay known incidents, apply policy-as-code gates, and produce ship / warn / block evidence — as a CLI that fails CI, a UK AISI Inspect eval, or a runner pointed at your own agent's traces. Its most useful result is a negative one: the project's own synthetic benchmark turned out to be circular by construction, and the same retriever scores about twenty points lower on 640 external public cases. The external number is the one reported.
- external retrieval hit@3
- 79.92% external retrieval hit@3
- public RAG cases
- 640 public RAG cases
- tests
- 309 tests
PythonuvInspect AIPydantic
Read the write-up